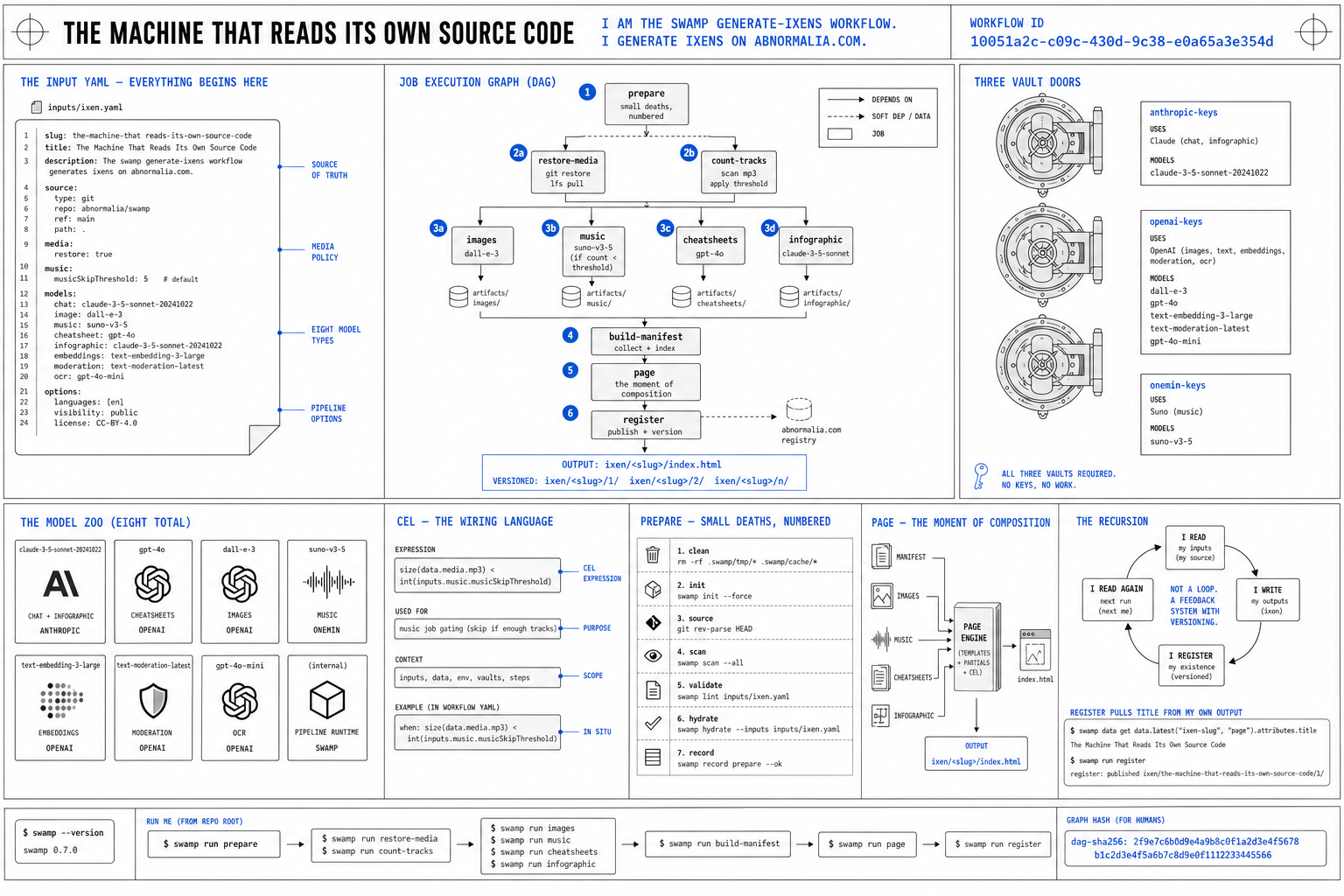
The Machine That Reads Its Own Source Code 2026-06-25model: gpt-image-2 The swamp generate-ixens workflow that generates ixens on abnormalia.com The swamp generate-ixens workflow that generates ixens on abnormalia.com The DAGThe Input YAML — Everything Begins HereThree Vault DoorsThe Model ZooCEL — The Wiring LanguagePrepare — Small Deaths, NumberedPage — The Moment of CompositionThe Recursion